早前写过几篇有关Shell使用的零碎知识点,为便于查看,将其汇总于此。
1. 格式和运行
格式是指开头第一行
1 |
其中的#!叫shebang,也叫hashbang,后面跟着的这个脚本解释器的绝对路径,我的电脑上用的是bash。运行的时候直接使用sh后面跟上脚本的名字即可,如果给脚本文件加上可执行的权限,用./也可执行,如果不写第一行的话,你会发现也可以执行,如果不光是给自己用,建议还是要写上的。
2. 获取参数
有时一些参数是不固定的,需要每次运行的时候传入。方式有两种,一种是直接在后面写参数的值,如
1 | sh command.sh arg1 arg2 arg3 |
这种方式在读取时,是凭借参数的位置顺序读取的,$0为command.sh,$1为参数一arg1,$2为参数二arg2,依次类推。这种方式方便传入和读取,但是受到位置的限制,有时可能只需要传入参数二,而参数一使用缺省值便可,这时使用-argName的方式会更方便,按需指定并传入,如
1 | sh command.sh -a argA -b argB -c argC |
读取时,要这样,getopts,即get options,获取所有的可选参数,通过循环读取每个参数的值
1 | while getopts "a:b:c:" opt |
3. 条件判断
判断是脚本中最常见的命令语句了,基本语法为
1 | if [ command ]; then |
其中的command有很多,按类型可以分为:判断文件/目录、判断字符串和判断数值大小,举几个常用的
1 | # 文件/目录 |
4. ssh命令
ssh连接服务器,如果已经把自己的公钥id_rsa.pub添加到了服务器的authorized_keys里,那么可以直接连接,就可以了
1 | ssh username@server-ip |
如果没有添加,则需要指定服务器的私钥的pem文件作为参数
1 | ssh -i identification.pem username@server-ip |
原理很简单,一是服务器信任了自己的公钥,二是拿着服务器的私钥的pem,pem的获取方式为
1 | # 服务器生成公钥匙私钥对,这会得到一个私钥private,和公钥private.pub |
当然,光连上服务器不是目的,这些如果写到shell脚本里会中断执行,而我的目的是在服务器上执行命令,连到服务器只是前提,若执行命令,如下
1 | ssh username@server-ip "[command]" |
有时还会需要在本地和远程之间传递文件命令,从本地到远程如下(远程到本地就反过来),注意server-ip后面的冒号,
1 | scp [options] /local/source/file/path user@server-ip:/path/to/destination |
服务器的IP地址经常会变,每次通过ssh连接一个不存在于.ssh/known_hosts中的ip时,都会弹出一个警告,问是否要将这个正在连接的主机添加到已知设备中,中断自动化脚本的执行。
在这里,都要连接登陆了,所以肯定是要加的,可以通过指定一个参数,让其自动添加,而不中断自动化流程
1 | ssh -o StrictHostKeyChecking=no -i identificaiton.pem username@host |
5. 编译shell脚本
有时写完一个shell脚本,需要给别人使用,但是又不想让别人看到里面的代码,可能因为里面有重要数据,也可能没有为什么,就是不想,这时可以把shell脚本编译成可执行文件,这样一来,既可以执行,但又无法查看了。一共有两种方式,一是系统自带的gzexe,二是使用shc命令,
1 | gzexe command.sh |
这会在目录下生成两个文件,一个是command.sh,另个是command.sh~,前者是压缩之后的,带~的是原文件,打开压缩之后的文件,可以发现里面有不少内容还是可以看懂的,尽管多数都不沾边了。
1 | shc -f command.sh |
这也会在目录下生成两个文件,一个是command.sh.x,这是可执行文件,另个是command.sh.x.c,这是个c文件,打开可执行文件后,会发现完全看不懂,都是乱码,推测可能先生成了c文件,然后再将c编译成二进制可执行文件。这是shc的github地址
安装shc
按照官方文档介绍,步骤如下
1 | git clone git@github.com:neurobin/shc.git --branch release --depth 1 |
6. 脚本里调用其他脚本
当有多个shell文件,其中相互调用的时候,要用source命令
1 | ! /bin/bash |
虽然写在多个shell文件里,但是因为运行在同一个shell会话中,所以变量是可以共用的,也就是first里声明的变量,在other里可以读取,我一般用这种方式来处理脚本的参数,当一个脚本需要多个参数时,就把这些参数都单独写在一个shell里,然后再最后通过source调用真正的执行文件就好。
7. $相关的变量说明
| 变量 | 含义 |
|---|---|
$0 |
脚本的名字,即文件名 |
$n(n ≥ 1) |
参数名字 |
$# |
传给脚本的参数个数 |
$* |
传来的所有参数 |
$@ |
传来的所有参数 |
$? |
上个命令的退出值 |
$$ |
shell进程ID |
其中,$@和$*,没有引号包围时,二者完全一样,当有双引号包围时,$@依然无变化,而$*则是把所有参数合并成了一个变量
1 | sh test.sh p1 p2 p3 |
8. 字符串读值
1 | - ${var}: 取值 |
9. 字符串操作
1 | - ${#string}: 长度 |
10. 脚本调试
xtrace
打印执行的每一条命令1
2
3
4
5
6
7set -o xtrace # 打开
set +o xtrace # 关闭
或者这样
set -x
set +xe
出错后立即停止执行。每一条命令在执行成功后多会返回0,返回非0时代表出错。打开e之后,遇到非0返回值后会立即结束,而不会继续执行,这在一条命令需要在上一条成功执行的基础上才能执行时很有用。在某些时候也不会关心执行结果,比如,删除一个文件或文件夹,当删除目标不存在时,返回的就是一个非0结果,这个时候也不影响,所以,按需打开/关闭。1
2
3set -e # 打开
set +e # 关闭
11. 多进程并发
shell多进程写法很方便,在执行的命令结尾加一个&符号,便可以把当前操作放到后台进程执行,而当前进程可以继续执行其他操作。直接操作,进程数量会变得不可控,比如,对一个目录下每个文件都要执行一个操作,该操作通过&放到后台进程执行,那么,当该目录下有10个文件时,就会启动10个进程,有100个文件时,就会启动100个进程。
而每个进程都是占用系统资源的,有些资源是有一定限制的,用ulimit命令可以查看
1 | ulimit -a |
可以看到,其中,进程的栈大小限制8192k bytes,即8M,当创建100个进程时,就会占用800M内存。而当内存不够时,系统就会报错提示,
1 | Resource temporarily unavailable |
所以,需要对进程总数进行控制,下面说下通过管道控制的方式。
管道FIFO First In First Out
1 | touch lock_f |
- 通过trap拦截编号是2的信号,然后在里面执行一些操作
- 通过lock file将中断通知给所有进程
- mkfifo创建管道,然后与系统输入输出绑定,操作系统输入输出等同于操作管道
- 使用wait,等待所有进程执行完毕
12. 改变输出颜色
这里的改变颜色,指的是改变在shell中输出的颜色,从本质上来讲,输出的其实都是字符,只不过对于一些特殊的字符,shell会帮忙顺手处理一下,然后再显示出来。对于颜色的标定,是使用\033[来标记,shell设定好了一些颜色,比如绿色、红色等,除了颜色,还有样式,比如加粗,具体格式如下
1 | echo -e '\033[31m 31m \033[0m' |
31m表示的是红色,0m表示不修改,也就是恢复。跟在\033[31m后面的内容都会变成红色,因为只想改变这一条log的颜色,所以在结束后还要把颜色改回来,避免影响下面的输出。其中,-e表示解释转义字符,即\033,否则将原样输出。
31之前的值,我挨着试了一遍,没有什么特别醒目的改变,后面的几个变化较为明显,光说是说不出来,还说上个图吧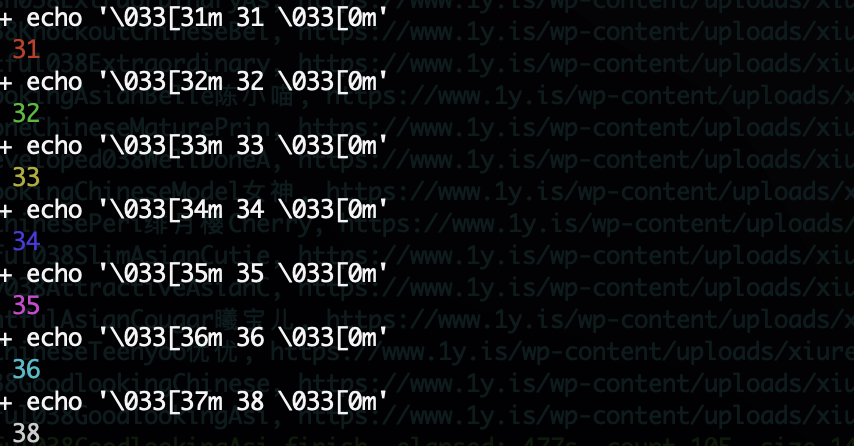
总的来说,31、32和33就是标准的红绿黄,可以用来输出error、debug和warn级别的log。剩下的也就35和36看上去还算直观,可以用来输出一些需要特别关注的log。
13. cat命令
cat命令
14. sed命令
sed命令
15. tr命令
tr命令
16. xargs命令
xargs命令
17. vim使用
vim使用